OCR识别
背景
传统的 OCR 方案大多采用谷歌 OCR(Tesseract)方案,但是它对于中文的识别非常差,经过大量的调研,我们使用 PaddleOCR,它是一个开源的基于深度学习的 OCR 识别工具,也是 PaddlePaddle 最有名的一个开源项目,感兴趣的可以点这里了解,多的不说了,你只需要知道它就是中文识别的天花板。
实现原理
安装它是个很麻烦的事情,虽然操作很简单,但其实安装包有点大,这并不符合我们对框架依赖治理的理解,我们并不希望直接在 env.sh 中加入它,这会让整个自动化环境变得非常臃肿;
因此,我们想到将它做成一个 RPC 服务在其他机器上部署,测试机通过远程调用 RPC 服务的方式使用它;
RPC 的调用逻辑:

这样我们只需要在服务端部署好 OCR 识别的服务,然后通过 RPC 服务将功能提供出来,框架里面只需要调用对应的 RPC 接口就行了。
使用说明
框架代码示意(Client):
from src import OCR
OCR.ocr(*target_strings, picture_abspath=None, similarity=0.6, return_default=False, return_first=False, lang="ch"):
# 通过 OCR 进行识别。
# target_strings:
# 目标字符,识别一个字符串或多个字符串,并返回其在图片中的坐标;
# 如果不传参,返回图片中识别到的所有字符串。
# picture_abspath: 要识别的图片路径,如果不传默认截取全屏识别。
# similarity: 匹配度。
# return_default: 返回识别的原生数据。
# return_first: 只返回第一个,默认为 False,返回识别到的所有数据。
# lang: `ch`, `en`, `fr`, `german`, `korean`, `japan`服务端代码示意(Service):
from socketserver import ThreadingMixIn
from xmlrpc.server import SimpleXMLRPCServer
from paddleocr import PaddleOCR
class ThreadXMLRPCServer(ThreadingMixIn, SimpleXMLRPCServer):
pass
CURRENT_DIR = dirname(abspath(__file__))
def image_put(data):
"""上传图片"""
def paddle_ocr(pic_path, lang):
"""
Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
:param file_name:
:param lang:
:return:
"""
if __name__ == "__main__":
IP = popen("hostname -I").read().split(" ")[0]
PORT = 8890
SCREEN_CACHE = "/tmp/screen.png"
server = ThreadXMLRPCServer((IP, PORT), allow_none=True)
server.register_function(image_put, "image_put")
server.register_function(paddle_ocr, "paddle_ocr")
print("监听客户端请求。。")
server.serve_forever()此方案在框架内没有引入任何三方依赖完全采用标准库实现,而且使用方法非常简单,只需要通过 OCR.ocr() 即可;
对于一些文案的场景非常适用,此方法直接返回坐标,可以用于元素定位。
也可以用于文字断言,代码示意:
def assert_ocr_exist(
*args, picture_abspath=None, similarity=0.6, return_first=False, lang="ch"
):
"""断言文案存在"""
pic = None
if picture_abspath is not None:
pic = picture_abspath + ".png"
res = OCR.ocr(
*args,
picture_abspath=pic,
similarity=similarity,
return_first=return_first,
lang=lang,
)
if res is False:
raise AssertionError(
(f"通过OCR未识别到:{args}", f"{pic if pic else GlobalConfig.SCREEN_CACHE}")
)
if isinstance(res, tuple):
pass
elif isinstance(res, dict) and False in res.values():
res = filter(lambda x: x[1] is False, res.items())
raise AssertionError(
(
f"通过OCR未识别到:{dict(res)}",
f"{pic if pic else GlobalConfig.SCREEN_CACHE}",
)
)在用例中使用断言,示例:
def test_font_manager_021(self):
"""右侧♥-收藏/取消收藏字体"""
# 字体管理器界面右侧详情列表,选择未收藏字体,右键 / 收藏字体
# 收藏字体,右键菜单显示“取消收藏”;
...
self.assert_ocr_exist("取消收藏")RPC服务端部署
服务端参考插件 pdocr-rpc 文档。
负载均衡
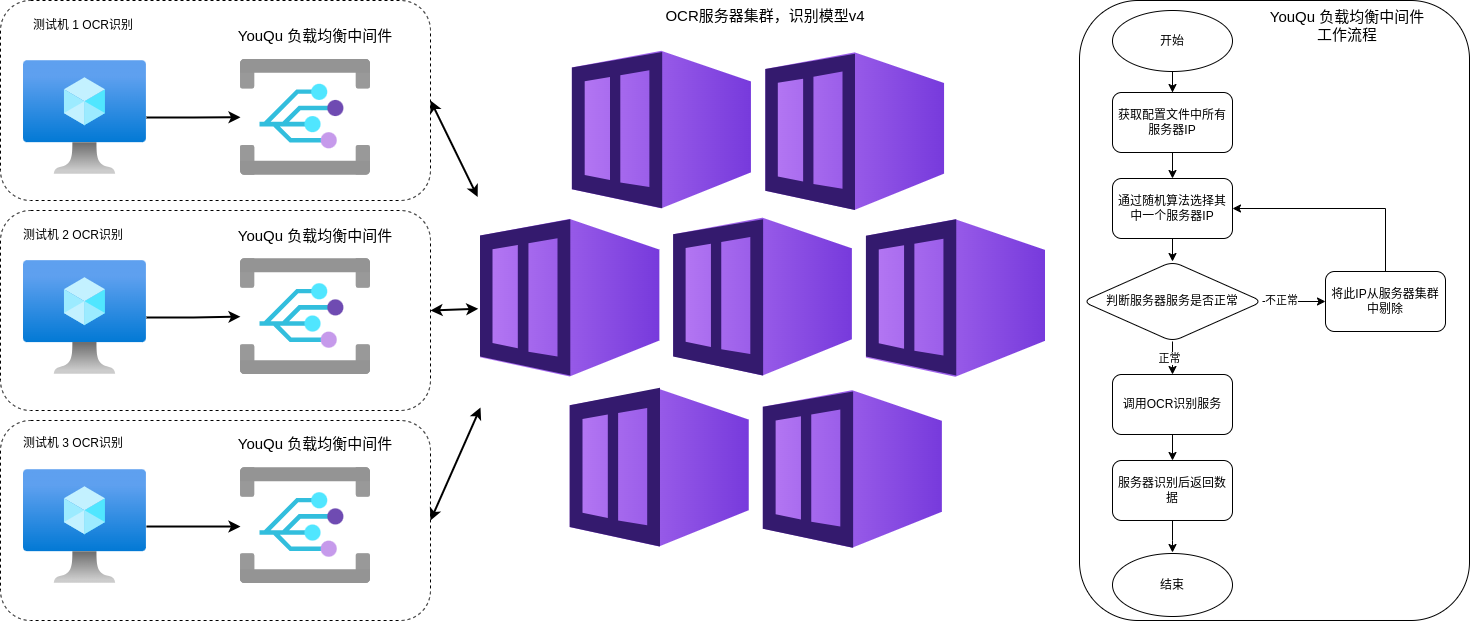
随着 OCR 服务在自动化测试子项目中被广泛使用,单台服务远不能满足业务需求,因此我们需要将 OCR 服务做分布式集群化部署,然后通过负载均衡技术将业务请求分发到 OCR 服务器上。
为什么基于 Nginx 的负载均衡方案不能满足业务需求
- 每次
OCR识别业务实际是两次RPC接口请求,第 1 次是将当前屏幕截图并发送到PRC服务器,第 2 次调用识别的接口做识别,采用 Nginx 轮询算法做负载均衡会出现两次RPC请求被分发到两台不同的服务器上,这明显是错误的。 - 基于 Nginx
ip_hash的session管理负载均衡算法时,Nginx 默认取 IP 的前 3 段做哈希,而我们的测试机都在同一个网段,IP 前 3 段是一样的,因此会导致负载不均衡。
YouQu 的解决方案
为了解决上面 2 个问题,YouQu 在 ocr_utils 模块对 pdocr-rpc 功能进行了增强,实现了一个中间件用以在用例跑测过程中对 OCR 服务集群进行负载均衡。
链式调用
YouQu OCR 支持链式调用函数接口,使用更方便更符合语义,原函数接口使用方法不变以保持兼容性。
from src import OCR
# 新的函数接口ocrx,支持链式调用
OCR.ocrx("确定").click()
OCR.ocrx("确定").center()
OCR.ocrx("确定").right_click()
OCR.ocrx("确定").double_click()
# 原函数接口ocr,返回坐标
OCR.ocr("确定")